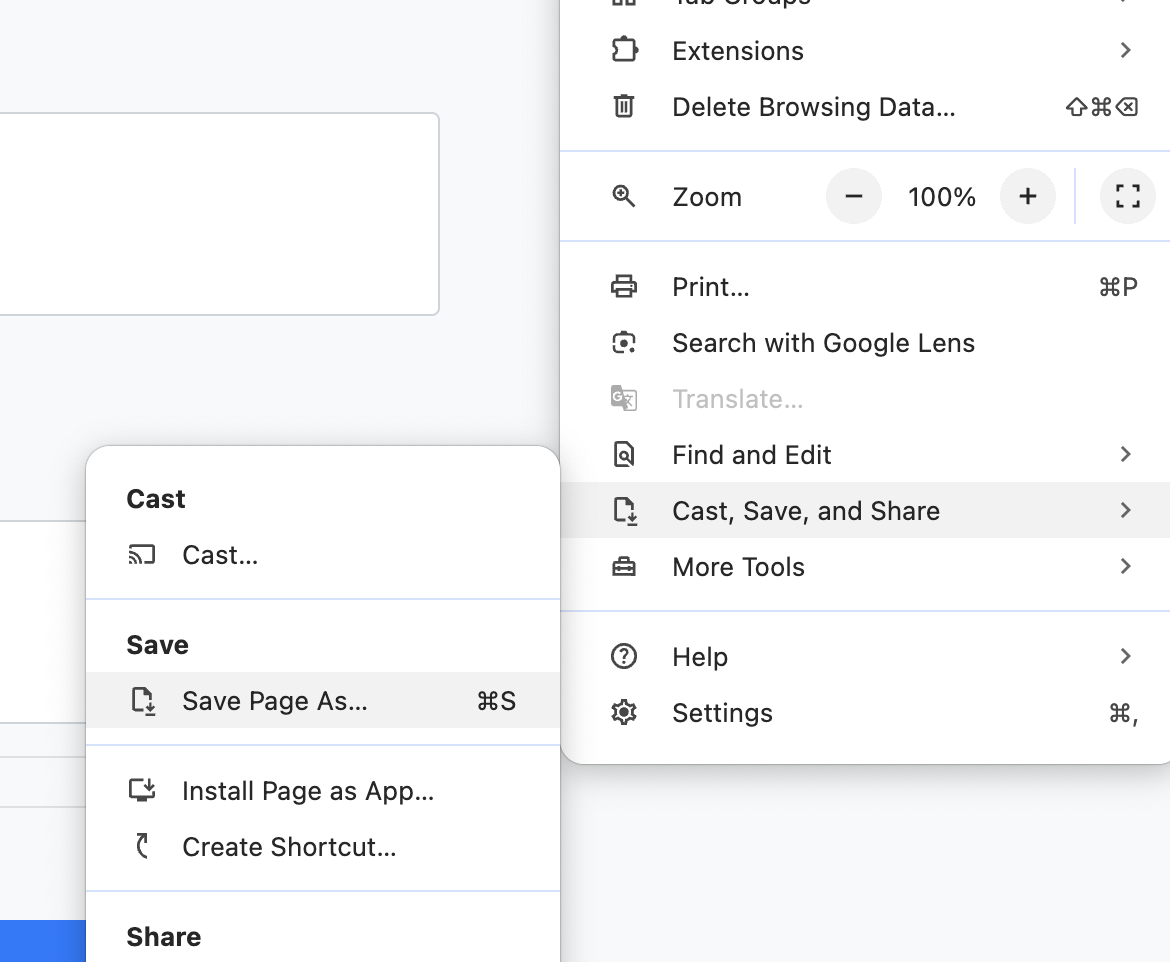
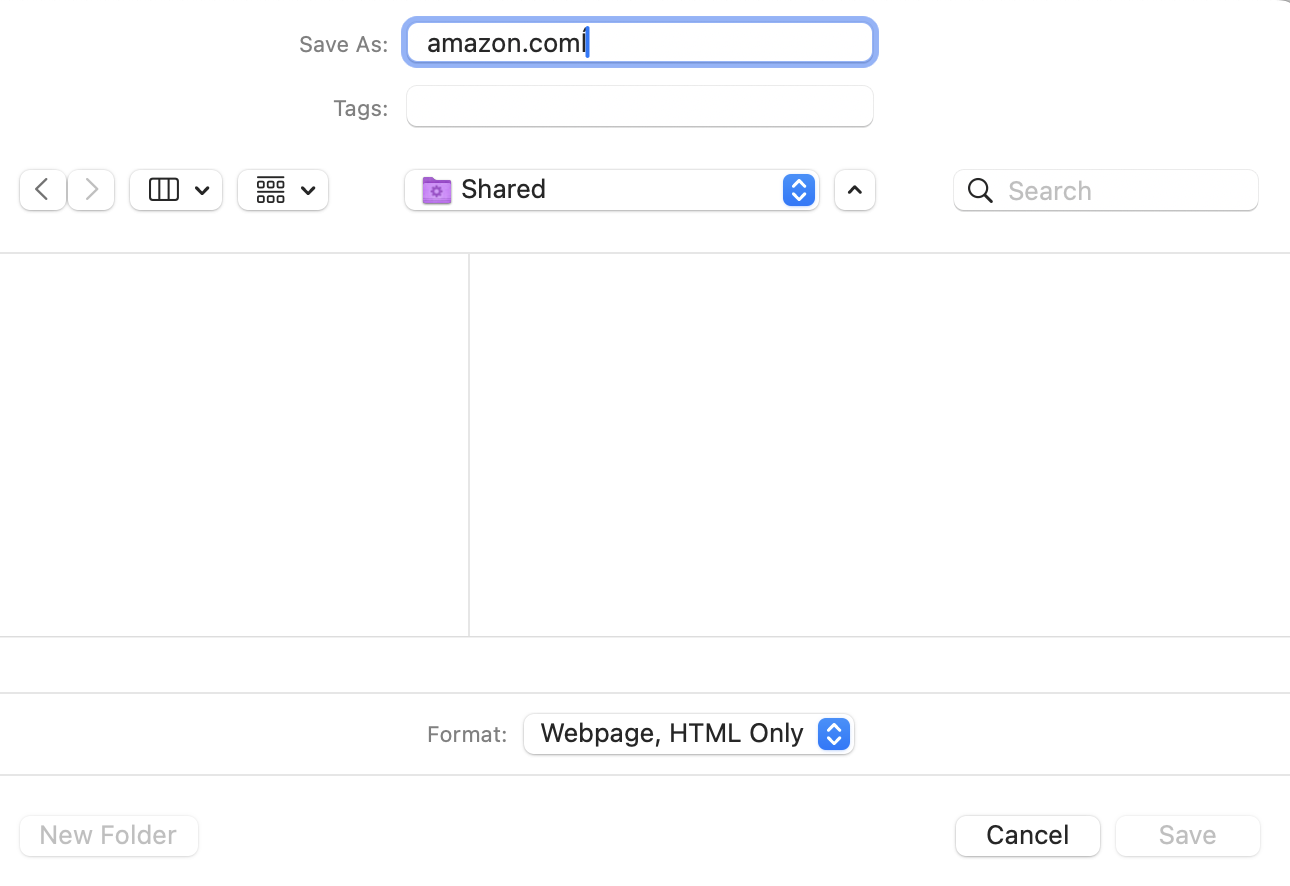
Upload Html When training is "Fail to Load"
When the training is "Fail to Load", Usually it is because our html downloader is banned by target website. No worry ,just need few pages to train. you can following below screenshot to save html and upload the file to Coparser. The Coparser will use the html file to train the model.
Install Python Libraries:
To install additional packages like lxml and playwright to run generated code:
# Install lxml
pip install lxml
# Install playwright
pip install playwright
# Install browsers
playwright install chromium
Notices:
1. The code is generated by a AI Agent. Hallucinations sometime happend. Please review the code before executing it. You run the code at your own risk. 🤖🪴🐎
2. This is a experimental service, so the capacity and service level are limited. 
- In theory, the more websites it is trained on, the better the generated code will work. Currently, it is limited to 2-3 websites.
- You can use the generated code in any scenarios, including commercial usage. However, I am not responsible for any legal issues that may arise from the use of the code.
- The parser is generated in a single thread. If it works well, it should create a parser in a few minutes.
- Post here to Ask for new feature ,More prompts will come soon.
- If you need a paid service, send email to [email protected]
3. There are some tasks to complete before putting it into production, such as implementing anti-bot measures and improving performance.