Parser only can be modify by owner ,Login to create your own parser. Google Login
| Parser No | 23d41811 | Created By: | coparser@2024-12-30 16:50:56 | Status: | code_gen | ||
|---|---|---|---|---|---|---|---|
| Prompt | Create python to extract product detail | ||||||
| Description | www.ebay.com product lenovo ebay thinkpad laptop | ||||||
| Training Cases: |
|
||||||
| Buy me a Coffe: |  |
||||||
| Action: |
|
||||||
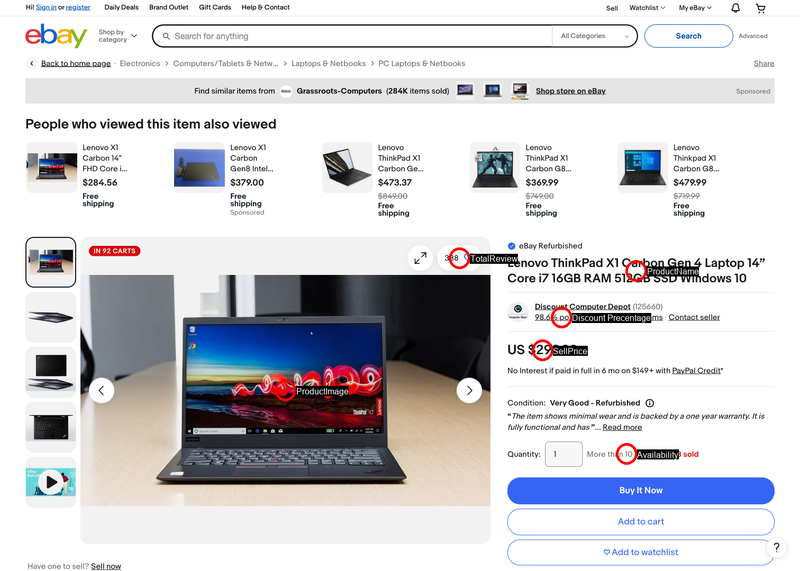
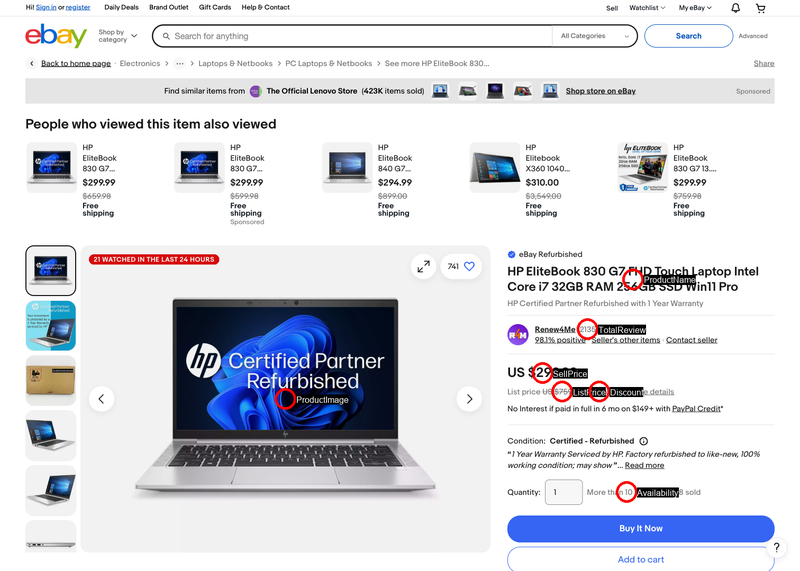
Source Code:
#Code Generated by Parser:23d41811 Rule: 2025-01-08 13:58:44
def get_html(url):
import time
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto(url)
time.sleep(10)
page_source = page.content()
browser.close()
with open("debug.html", "w", encoding="utf-8") as file:
file.write(page_source)
return page_source
def extract_ListPrice(lxml_tree):
from lxml.cssselect import CSSSelector
import re
from decimal import Decimal
selector = CSSSelector("ul.carousel__list span.sh-strikethrough.sh-secondary")
elements = selector(lxml_tree)
if elements:
raw_price = elements[0].text_content()
cleaned_price = re.sub(r"[^\d.]", "", raw_price)
return Decimal(cleaned_price)
return None
def extract_SellPrice(lxml_tree):
from lxml.cssselect import CSSSelector
import re
from decimal import Decimal
selector = CSSSelector("div.x-bin-price__content span.ux-textspans")
elements = selector(lxml_tree)
if elements:
raw_price = elements[0].text_content()
cleaned_price = re.sub(r"[^\d.]", "", raw_price).replace("..", ".")
return Decimal(cleaned_price)
return None
def extract_ProductName(lxml_tree):
from lxml.cssselect import CSSSelector
import re
selector = CSSSelector('div.x-item-title h1.x-item-title__mainTitle span.ux-textspans--BOLD')
result = selector(lxml_tree)
return re.sub(r'\s+', ' ', result[0].text_content().strip()) if result else None
def extract_TotalReview(lxml_tree):
from lxml.cssselect import CSSSelector
import re
selector = CSSSelector('div.x-sellercard-atf__about-seller li span.ux-textspans--SECONDARY')
result = selector(lxml_tree)
match = re.search(r'\((\d+)\)', result[0].text_content()) if result else None
return int(match.group(1)) if match else None
def extract_Availability(lxml_tree):
from lxml.cssselect import CSSSelector
selector = CSSSelector('div.x-quantity__availability span.ux-textspans--SECONDARY')
result = selector(lxml_tree)
return result[0].text_content().strip() if result else True
def extract_ProductImage(lxml_tree):
from lxml.cssselect import CSSSelector
selector = CSSSelector('div.ux-image-carousel-item img')
result = selector(lxml_tree)
return result[0].get('src') if result else None
if __name__ == '__main__':
import lxml.html
url='https://www.ebay.com/itm/176714178727'
html=get_html(url)
tree = lxml.html.fromstring(html)
result={}
result['ListPrice']=extract_ListPrice(tree)
result['SellPrice']=extract_SellPrice(tree)
result['ProductName']=extract_ProductName(tree)
result['TotalReview']=extract_TotalReview(tree)
result['Availability']=extract_Availability(tree)
result['ProductImage']=extract_ProductImage(tree)
print(result)